最近在给公司的内容服务做性能优化,发现了spring data redis中的一个序列化深坑,导致codis集群里保存的kv数据都多进行了一次序列化,存储空间和服务响应时间都被白白增加。查看了源码和文档之后才理清楚。
发现问题
由于某关键的底层服务(主要任务就是读codis,然后做一些流的拼接)响应速度太慢,老大让研究一下怎么改造。由于该服务逻辑比较简单,简单分析之后觉得有可能是原先spring的框架过重,于是打算使用别的语言重构一下。
在使用golang进行服务重构的时候总是无法从codis返回的字节码中解析出ProtoBuf中定义的Message对象,下载了一个RedisDesktopManager,简单查看了一下codis上的数据,吓了一跳。所有的数据的前面都被插入了一些奇怪的16进制字符,而且基本都很有规律。由于读写的项目中都使用了spring data redis,所以从源码出发,看看读写操作具体发生了什么。
源码分析
检查项目配置
参考spring data redis的文档,项目中是这么使用的
-
1
2
3
4
5
6
7
8
9
10
public class RedisConf {
public RedisTemplate<String, byte[]> stringBytesRedisTemplate(JedisConnectionFactory jedisConnectionFactory) {
RedisTemplate<String, byte[]> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(jedisConnectionFactory);
return redisTemplate;
}
} 然后通过这个模板,配置了一个string/value类型的操作
1
2(name = "stringBytesRedisTemplate")
private ValueOperations<String, byte[]> valueOperations;之后可以使用这个operation进行读写操作
读操作
1
2
3
4
5
6
7
8
9
10
11List<byte[]> values = valueOperations.multiGet(keys);
NewsReply.Builder builder = NewsReply.newBuilder();
for (byte[] value : values) {
try {
MpNews mpNews = MpNews.parseFrom(value);
builder.addValues(mpNews);
} catch (Exception e) {
logger.error("error:", e);
}
}可以看到先用valueOperations的multiGet从codis中读取数据,然后解析成mpNews
写操作
1
2
3
4
5
6
7
8
9
10
11
12public void storeMpNews(MpNews mpNews) {
String cacheKey = createKey(mpNews.getId());
byte[] bytes = ProtobuffUtil.serializerMpNews(mpNews);
storeValue(cacheKey, bytes);
}
protected void storeValue(String key, byte[] bytes) {
try {
valueOperations().set(key, bytes);
} catch (Exception e) {
log.error("error when store values to redis for key: " + key, e);
}
}可以看到先用ProtobuffUtil进行了protolbuf的序列化,然后再使用valueOperations的set操作写入codis
乍一看写操作和读操作的配置和使用都没什么问题,但是由于codis上的数据确实存在问题了,因此需要继续深入检查写操作
深入定位读写操作
检查soreValue中valueOperation的set操作(回顾上一节的2,valueOperation是由我们配置的)
1
2
3
4
5
6
7
8
9
10public void set(K key, V value) {
final byte[] rawValue = rawValue(value);
execute(new ValueDeserializingRedisCallback(key) {
protected byte[] inRedis(byte[] rawKey, RedisConnection connection) {
connection.set(rawKey, rawValue);
return null;
}
}, true);
}这个rawValue是什么鬼,真的是rawValue吗?
检查rawValue
1
2
3
4
5
6byte[] rawValue(Object value) {
if (valueSerializer() == null && value instanceof byte[]) {
return (byte[]) value;
}
return valueSerializer().serialize(value);
}哈哈果然调用了一个序列化的东东
检查调用的序列化
1
2
3
4
5
6
7
8
9
10
11RedisSerializer valueSerializer() {
return template.getValueSerializer();
}
/**
* Returns the value serializer used by this template.
*
* @return the value serializer used by this template.
*/
public RedisSerializer<?> getValueSerializer() {
return valueSerializer;
}果然问题出现在这个valueSerializer里
深入定位序列化
我们来深入看一下RedisTemplate的配置过程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42public void afterPropertiesSet() {
super.afterPropertiesSet();
boolean defaultUsed = false;
if (defaultSerializer == null) {
defaultSerializer = new JdkSerializationRedisSerializer(
classLoader != null ? classLoader : this.getClass().getClassLoader());
}
if (enableDefaultSerializer) {
if (keySerializer == null) {
keySerializer = defaultSerializer;
defaultUsed = true;
}
if (valueSerializer == null) {
valueSerializer = defaultSerializer;
defaultUsed = true;
}
if (hashKeySerializer == null) {
hashKeySerializer = defaultSerializer;
defaultUsed = true;
}
if (hashValueSerializer == null) {
hashValueSerializer = defaultSerializer;
defaultUsed = true;
}
}
if (enableDefaultSerializer && defaultUsed) {
Assert.notNull(defaultSerializer, "default serializer null and not all serializers initialized");
}
if (scriptExecutor == null) {
this.scriptExecutor = new DefaultScriptExecutor<K>(this);
}
initialized = true;
}
而这个enableDefaultSerializer是默认打开的1
private boolean enableDefaultSerializer = true;
这下水落石出了,原因在于之前RedisTemplate的配置默认使用了jdk的序列化。最终导致:
- 写操作时
message object ==protobuf序列化==> []byte ==jdkSerializer==> XXX ==写入==> codis - 读操作时
message object <==protobuf序列化== []byte <==jdkSerializer== XXX <==读出== codis
由于读写操作都使用了默认的相同配置,系统一直正常运行,因此没有出现任何问题。
看了一下文档果然提到了这个问题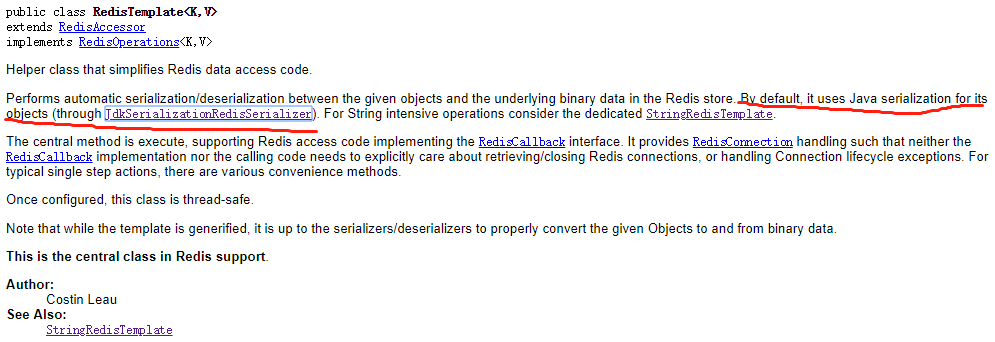
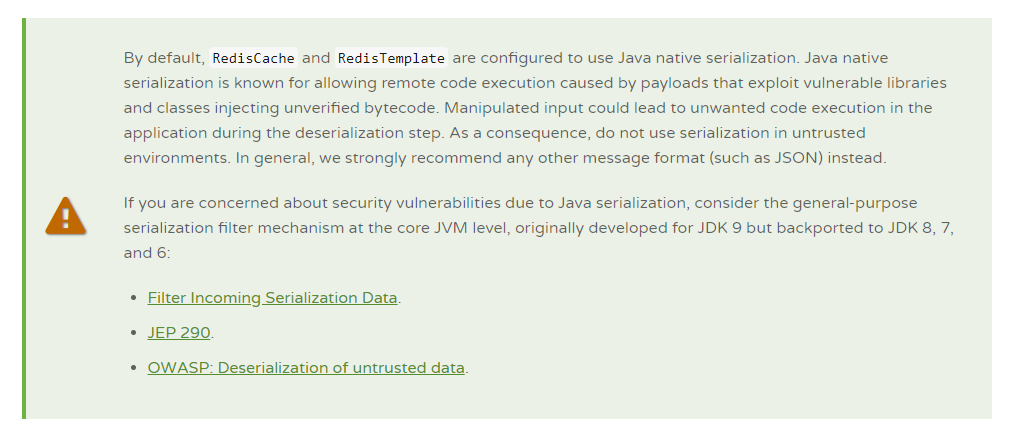
解决问题
发现bug之后,修正配置变得特别方便,最主要的困难是线上数据的清洗
配置修正
加一行代码关闭默认序列化1
2
3
4
5
6
7
8
9
10
11
public class RedisConf {
public RedisTemplate<String, byte[]> stringBytesRedisTemplate(JedisConnectionFactory jedisConnectionFactory) {
RedisTemplate<String, byte[]> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(jedisConnectionFactory);
redisTemplate.setEnableDefaultSerializer(false);
return redisTemplate;
}
}
线上数据清洗
由于线上数据有两套codis A和B,我们先把所有服务都使用A,然后清洗B中的数据,然后用修改后的服务连接B。最后我们把旧的服务全下线,清洗A,再上线新服务连接A。中间逻辑注意双写。
这样就实现了清洗数据时服务的无缝切换。
其它项目使用错误数据
如果线上数据来不及清洗,同时其它java项目需要读取当前线上的错误数据,那么可以把读出来的数据进行一次反序列化处理。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18private static Object unserialize(byte[] bytes) {
ByteArrayInputStream bais = null;
try {
// 反序列化
bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
} catch (Exception e) {
logger.error("{}", e);
} finally {
try {
bais.close();
} catch (IOException e) {
logger.error("{}", e);
}
}
return null;
}


